
The application of deep learning approaches to bioimage analysis has been growing in prevalence for several years, expanding the scope of experimental possibilities. Deep learning is a type of machine learning that uses artificial neural networks (ANNs), also called convolutional neural networks (CNNs), to learn how to perform a given task entirely from a set of provided data. In a supervised deep learning model—the kind most widely employed in biomedical approaches—the data on which the model learns on is called the training set and must be manually annotated. It’s well-established that the quality of the training set is critical to a successful model, but making a good training set for a given task is often the biggest bottleneck.
For example, the task we want to achieve might be identifying all the images of cats in a collection of 10,000 memes pulled from the internet. We would probably choose to train the model on a set of memes that we have individually gone through and identified as cat-containing or non-cat-containing, but we need to be sure the memes we are training on are similar enough to allow our model to make good predictions on an unknown set of memes. For example, we must include both cartoon and real cat images, cats in different positions, cats of different colors, and both cat faces and cat bodies. Obviously, this takes some thought and effort.
Let’s bring this closer to a real-life scientific application. Say you have a new compound, treatment, or genetic manipulation, and you’d like to see how it affects cellular growth. Perhaps you take a series of light microscope images of your experimental conditions, every few hours until confluence is reached. Or, if your lab has invested in new technology such as the Incucyte to automatically image plates of growing cells, you walk away and come back 2 days later to a file containing dozens to hundreds of images. Now, say you want to count the number of cells in each image to compare growth curves. You can choose to manually annotate—go through each image and determine what constitutes a cell—but this is not really feasible or time-effective (depending on how large your dataset is). If you want to use a deep learning model to count your cells, you face a major problem (assuming you already know how to set up, train, and evaluate a CNN model—see this article or this one for that technical info). Is there a dataset available to train on that would be appropriate for the type of cell and image you’re working with? In this specific case—you’re in luck! A paper recently published in Nature Methods by Edlund et al. introduces LIVECell: a large, high-quality, manually annotated and expert-validated dataset of 1.6 million phase-contrast cell images taken by an Incucyte system and encompassing a wide range of morphologies and culture conditions. Full disclosure: most of the authors are affiliated with Sartorius, the company that makes the Incucyte.
Edlund et al. created a training dataset of label-free live cells (read: no fluorescent proteins or other forms of tagging) and trained a CNN-based model to evaluate the model’s cell segmentation accuracy. Given that most biological microscopy images consist of 2D monolayers—confluent or semi-confluent cells cultured on a flat surface such as a coverslip—this training set has potentially high applicability for cell segmentation and cell counting in diverse datasets despite lacking nuclear or cytoskeletal markers. Furthermore, label-free imaging can be advantageous (or the only option) in several contexts. For example, experimenters using primary cells which are refractory to genetic manipulation or who are mainly interested in cell growth or migration kinetics may choose not to use fluorescent tagging or fluorescent microscopy. Although many sophisticated techniques for label-free imaging exist (see this paper for examples), the most commonly used is basic phase-contrast light microscopy. Label-free cellular segmentation in light microscopy images is particularly challenging because of the limited contrast of images, and the scarcity of annotated datasets. Consequently, one of the stated goals of this work was to introduce a new dataset for label-free cell segmentation model training.
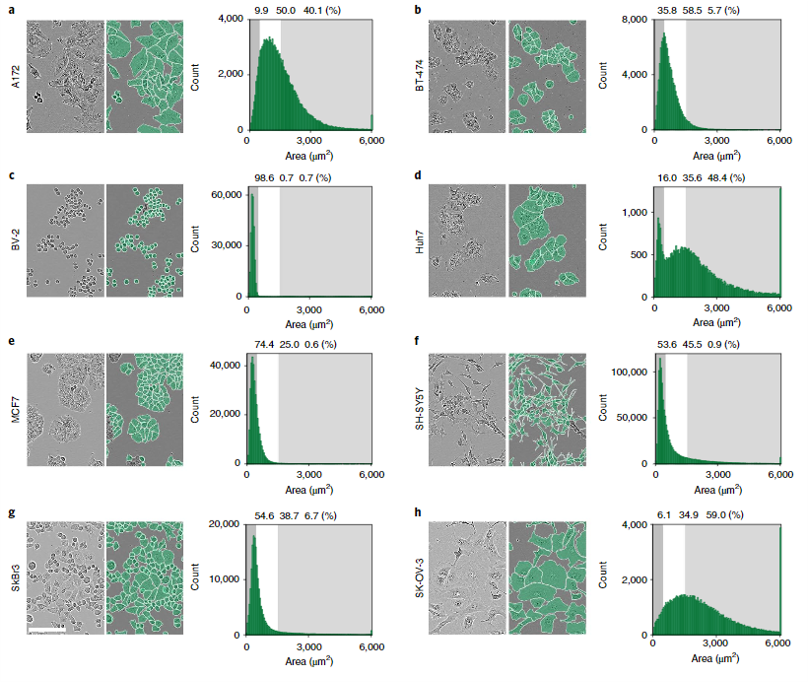
The authors generated 5,239 Incucyte HD phase-contrast images of 8 morphologically different cell types ranging from small and round BV-2 cells to neuronal-like SH-SY5Y. Specifically, Huh7, BV-2, BT-474, A172, MCF7, SH-SY5Y, SK-OV-3, and SKBr3 cell lines were imaged over the course of growth from initial seeding to full confluency. The resulting images were annotated by professional annotators from CloudFactory and then used to train two CNN models—one anchor-based and the other anchor-free. Anchor-based detection refers to a model where objects are located through a series of bounding rectangles whose parameters are pre-determined. These bounding boxes are “drawn” over the image and the most likely true object-containing boxes are selected as the model’s prediction. In the case of this segmentation algorithm, the predicted objects within the bounding boxes are outlined. For more on anchor-based detection, see this explainer. Anchor-free detection models do not use pre-defined anchor boxes but rather predict the center point of objects and work from there to draw bounding boxes.
The two models trained on the LIVECell dataset were evaluated using a series of benchmark tests, which included the following:
1. Training the models on the full LIVECell dataset, and evaluating cell segmentation on a test dataset with all 7 cell types represented as well as datasets containing only one cell type
2. Training the models on a subset of the LIVECell dataset containing only one cell type, and evaluating on a test set containing the same single cell type
3. Training the models on a subset of the LIVECell dataset containing only one cell type, and evaluating on test sets with only one cell type from among the 6 remaining
4. Training the models on the full LIVECell dataset and evaluating performance on different fluorescent image test datasets
Among the metrics reported were overall average precision (AP) and average false-negative ratio (AFNR).
Both models scored around 50% AP in the first benchmark test, although there were definite differences in their ability to segment different cell types. As would be expected, the models achieved lower precision for more complex, irregular neuronal-like cells and were very robust for more regular round cells. When trained on a single cell type, AP was still overall very good but ranged from 22-28% AP for neuronal-like cells to 64-66% AP for small round cells. The anchor and anchor-free models performed similarly across single cell types, and in all cases better APs were achieved when models were trained on all cells and tested on a single cell type than when trained on a single cell type and tested on a single cell type, suggesting a universal model makes better predictions. In terms of transferability, models trained on one cell type and applied to another cell type varied widely in AP and were in general less effective than the universal model. Scores ranged from 36% AP to as low as 10.1% AP depending on cell type. Finally, when the trained models were used to predict cell counts in fluorescent microscopy images from different datasets, very good accuracy was achieved. There was a >90% correlation between pre-determined fluorescent cell count and cell count based on model segmentation below 95% confluency, but as cell confluency increased above that threshold model performance decreased.
Interestingly, the authors also tried to determine the minimum number of training images needed for good model accuracy and found that in fact the segmentation AP score increased monotonically as a function of training set size without plateauing, indicating that an even larger training set could improve this model even further. And finally, the authors evaluated the performance of the LIVECell-trained models on test sets collected from other imaging platforms (namely, the EVICAN and Cellpose image collections) which included fluorescent and brightfield images. EVICAN is the largest manually annotated cellular image dataset to date, consisting 4,600 images and 26,000 cells. This dataset includes 30 different cell types and images acquired with different microscopes, modalities and magnifications. The CellPose dataset consists of ~70,000 segmented cells, most of which are fluorescently labeled with a few light microscopy images and noncellular objects as well. Because these test images were obtained on other microscopes and imaging platforms, the image formats were different enough from the training set to require pre-processing. The authors developed a preprocessing pipeline and applied it to the EVICAN and Cellpose datasets prior to use on the LIVECell-trained model—an important caveat for user applications of this training set.
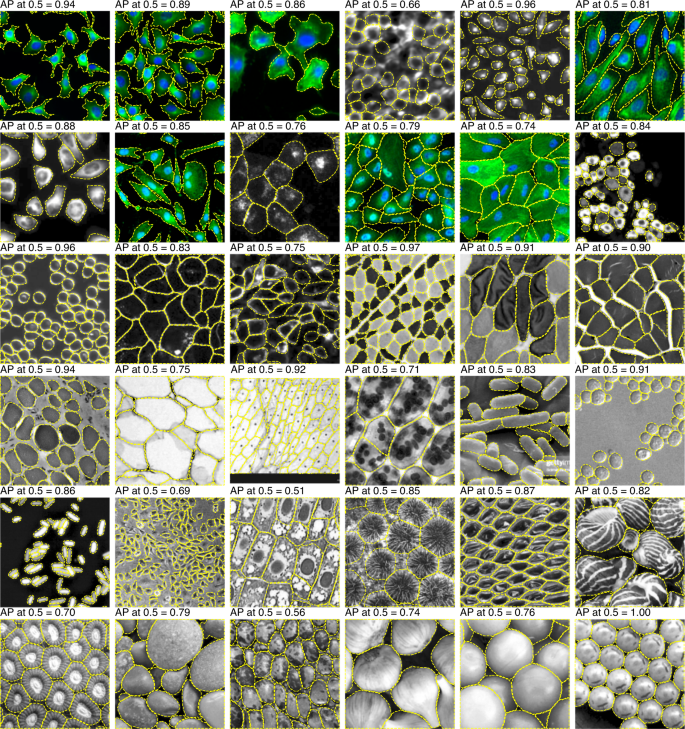
Overall, the LIVECell models performed well on both test sets, achieving an AP score of 36.7 and 59.6% (anchor-based and anchor-free, respectively) on the EVICAN easy evaluation dataset and 24.5% and 26.9% AP on the Cellpose dataset. Despite the fact that LIVECell contains only phase-contrast images the transferability of this training set to other types of images is relatively good, extending its usefulness for other applications.
Edlund et al.'s work represents a much-needed contribution to the image-analysis field. Large open-source curated datasets are critical for making AI-assisted analysis accessible to life scientists and encouraging machine learning scientists to continue to address biological questions and develop novel approaches. This paper also highlighted how far there is yet to go for accurate segmentation of certain cell type: asymmetrical and complex cells such as neurons and other dendrite-containing cells have been somewhat neglected by the field, despite the critical need to accurately identify neuronal bodies in studies of brain architecture, neurodegenerative diseases, and immune-brain interactions (among others).
If all this sounds great to you but you’re not ready to train your own CNN model just yet, Biodock can build you a custom AI module for any imaging application, including difficult-to-segment images as discussed above. We can label your data, produce a training set, and train a segmentation model unique to your dataset to reduce your analysis time by 95%! You can launch our AI models in an easy-to-use image analysis interface, so you don’t have to be a computer scientist to use it. Wherever you are in your image analysis journey, Biodock can help!